
Finding the best estimate for distribution of the population is done by maximum likelihood method. but the parameters that lead to this best distribution are sometimes biased estimators of the paraters themselves.
The method of Maximum Likelihood tries to find estimators for population parameters that create a distribution that maximizes the likelihood of observations statistics.
In maximum likelihood method, we choose the P1,P2, Pn parameteres of the population which maximize the likelihood of s1,s2,s3 statistics of samples condistional to p1,p2,p3 being the parameters of the population (Wackerly, D., Mendenhall, W., & Scheaffer, R. L. , 2001, p.449)
Continuous random variables X1, …, Xn are all statistically independent from each other if and only if their joint density function can be factored as:

- This means that the COV(Xi,Xj)=0 Johnson, R. A., & Wichern, D. W. 2007, p. 69)
Suppose there is a sample x1, x2, …, xn of n independent and identically distributed (iid) observations, coming from a distribution with an unknown probability distribution function pdf ƒ0(·). It is however surmised that the function ƒ0 belongs to a certain family of distributions {?ƒ(·|?), ? ? ??}, called the parametric model, so that ƒ0 = ƒ(·|?0). The value ?0 is unknown and is referred to as the “true value” of the parameter. It is desirable to find some estimator 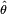 which would be as close to the true value ?0 as possible. Both the observed variables xi and the parameter ? can be vectors.
which would be as close to the true value ?0 as possible. Both the observed variables xi and the parameter ? can be vectors.
To use the method of maximum likelihood, one first specifies the joint density function for all observations. For an iid sample this joint density function will be
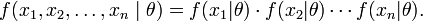
Now we look at this function from a different perspective by considering the observed values x1, x2, …, xn to be fixed “parameters” of this function, whereas ? will be the function’s variable and allowed to vary freely.
MLE was first suggested by Fisher in 1920s. A MLE estimate is the same whether we maximize the likelihood or the log-likelihood function, since log is a monotone funstion. In many situations we maximize the log of the likelihood since log converts multiplications to additions which are easier to work with (Devore, P. J. L. , 2007, p. 245).
=============================================================================
This example is from wikipedia:http://en.wikipedia.org/wiki/Maximum_likelihood#Continuous_distribution.2C_continuous_parameter_space
Continuous distribution, continuous parameter space
For the normal distribution 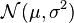 which has probability density function
which has probability density function

the corresponding probability density function for a sample of n independent identically distributed normal random variables (the likelihood) is

or more conveniently:

where 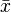 is the sample mean.
is the sample mean.
This family of distributions has two parameters: ? = (?, ?), so we maximize the likelihood, 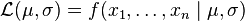 , over both parameters simultaneously, or if possible, individually.
, over both parameters simultaneously, or if possible, individually.
Since the logarithm is a continuous strictly increasing function over the range of the likelihood, the values which maximize the likelihood will also maximize its logarithm. Since maximizing the logarithm often requires simpler algebra, it is the logarithm which is maximized below. (Note: the log-likelihood is closely related to information entropy and Fisher information.)
![\begin{align} 0 & = \frac{\partial}{\partial \mu} \log \left( \left( \frac{1}{2\pi\sigma^2} \right)^{n/2} \exp\left(-\frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2}\right) \right) \\[6pt] & = \frac{\partial}{\partial \mu} \left( \log\left( \frac{1}{2\pi\sigma^2} \right)^{n/2} - \frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2} \right) \\[6pt] & = 0 - \frac{-2n(\bar{x}-\mu)}{2\sigma^2} \end{align}](http://upload.wikimedia.org/math/8/9/e/89e3e66bb7b8d209cb953e395faf4ba3.png)
which is solved by

This is indeed the maximum of the function since it is the only turning point in ? and the second derivative is strictly less than zero.
An estimator is said to be unbiased if its bias is equal to zero for all values of parameter ?.
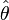 that maps observed data to values that we hope are close to ?. Then the bias of this estimator is defined to be
that maps observed data to values that we hope are close to ?. Then the bias of this estimator is defined to be
![\operatorname{Bias}[\,\hat\theta\,] = \operatorname{E}[\,\hat{\theta}\,]-\theta = \operatorname{E}[\, \hat\theta - \theta \,],](http://upload.wikimedia.org/math/7/e/9/7e921027cf07cd22d61f2affdf245016.png)
where E[ ] denotes expected value over the distribution P(x | ?), i.e. averaging over all possible observations x.
We can show that expected value is equal to the parameter ? of the given distribution, http://www.google.ca/url?sa=t&source=web&cd=2&ved=0CB4QFjAB&url=http%3A%2F%2Fclassweb.gmu.edu%2Ftkeller%2FHANDOUTS%2FHandout6.pdf&ei=O4pATsOwF8bSiALQwY3JBQ&usg=AFQjCNHy14oE99pDSgeMQmm_R3qks3oIGA&sig2=SpONA9WK-OOa9qneipefvA
![E \left[ \widehat\mu \right] = \mu, \,](http://upload.wikimedia.org/math/3/3/e/33eb258b6d0c1f03ae61f6fff75e11d6.png)
which means that the maximum-likelihood estimator  is unbiased.
is unbiased.
E(Xbar)
= E(1/n ? Xi)
= 1/n * E(?Xi)
expectation is a linear operator so we can take the sum out side of the argurement
= 1/n * ? E(Xi)
there are n terms in the sum and the E(Xi) is the same for all i
= 1/n * nE(Xi)
= E(Xi)
E(Xbar) = ?
since E(Xbar) = ?, Xbar is an unbiased estimator for the populaiton mean ?.
If we differentiate the log likelihood with respect to ? and equate to zero:
![\begin{align} 0 & = \frac{\partial}{\partial \sigma} \log \left( \left( \frac{1}{2\pi\sigma^2} \right)^{n/2} \exp\left(-\frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2}\right) \right) \\[6pt] & = \frac{\partial}{\partial \sigma} \left( \frac{n}{2}\log\left( \frac{1}{2\pi\sigma^2} \right) - \frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2} \right) \\[6pt] & = -\frac{n}{\sigma} + \frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{\sigma^3} \end{align}](http://upload.wikimedia.org/math/2/3/1/2316464fc710f37c9d8456cf16b306c4.png)
the solution is:
================================
We can show that this is a biased estimator 🙁
Inserting we obtain
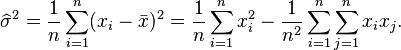
To calculate its expected value, it is convenient to rewrite the expression in terms of zero-mean random variables (statistical error)  . Expressing the estimate in these variables yields
. Expressing the estimate in these variables yields

Simplifying the expression above, utilizing the facts that ![E\left[\delta_i\right] = 0](http://upload.wikimedia.org/math/1/e/8/1e8fa4403ce5626dcd6288f3b46b9e79.png) and
and ![E[\delta_i^2] = \sigma^2](http://upload.wikimedia.org/math/7/0/a/70a488218f5c06e05db0900b82dce630.png) , allows us to obtain
, allows us to obtain
![E \left[ \widehat{\sigma^2} \right]= \frac{n-1}{n}\sigma^2.](http://upload.wikimedia.org/math/5/f/1/5f12695fa047df25116d1c266e9d5579.png)
This means that the estimator 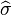 is biased. (It will under estimate the variance) However, is consistent.
is biased. (It will under estimate the variance) However, is consistent.
( In mathematical terms consistent means that as n goes to infinity the estimator converges in probability to its true value:  Under slightly stronger conditions, the estimator converges almost surely (or strongly) to:
Under slightly stronger conditions, the estimator converges almost surely (or strongly) to: 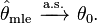 )Formally we say that the maximum likelihood estimator for ? = (?,?2) is:
)Formally we say that the maximum likelihood estimator for ? = (?,?2) is:

 when the sample size is less than infinity.
when the sample size is less than infinity.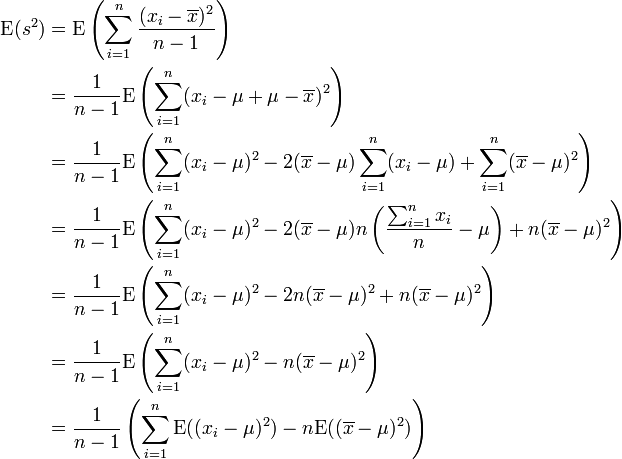
Note that, since x1, x2, · · · , xn are a random sample from a distribution with variance ?2, it follows that for each i = 1, 2, . . . , n:

- Wackerly, D., Mendenhall, W., & Scheaffer, R. L. (2001), p.372
and also

This is a property of the variance of uncorrelated variables, arising from the Bienaymé formula. For a proof, see here. The required result is then obtained by substituting these two formulae:
![\operatorname{E}(s^2) = \frac{1}{n-1}\left[\sum_{i=1}^n \sigma^2 - n(\sigma^2/n)\right] = \frac{1}{n-1}(n\sigma^2-\sigma^2) = \sigma^2. \,](http://upload.wikimedia.org/math/6/0/7/60701ebe5c824337f64e42ea690986ac.png)
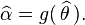
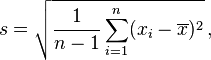
where  is the sample (formally, realizations from a random variable X) and
is the sample (formally, realizations from a random variable X) and 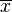 is the sample mean.
is the sample mean.
http://en.wikipedia.org/wiki/Unbiased_estimation_of_standard_deviation
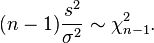
As a direct consequence, it follows that E(s2) = ?2
The Variance of sample variance will be (2*df) which will be 2*(n-1)
If the yi are independent and identically distributed, but not necessarily normally distributed, then
![\operatorname{E}[s^2] = \sigma^2, \quad \operatorname{Var}[s^2] = \sigma^4 \left( \frac{2}{n-1} + \frac{\kappa}{n} \right),](http://upload.wikimedia.org/math/3/f/a/3fa49e6d079f351dc8eee7bfd6a8d4aa.png)
where ? is the kurtosis of the distribution. If the conditions of the law of large numbers hold, s2 is a consistent estimator of ?2.
Johnson, R. A., & Wichern, D. W. (2007). Applied Multivariate Statistical Analysis (6th ed.). Prentice Hall.
![]()
Comments
Estimators for a population’s parameters — No Comments
HTML tags allowed in your comment: <a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>