
Data is better to be tab delimited than comma “,” delimited
R Data Types
http://www.statmethods.net/input/datatypes.html
R Courses
http://www-bcf.usc.edu/~gareth/ISL/ISLR%20First%20Printing.pdf
http://statweb.stanford.edu/~tibs/ElemStatLearn/
Carl James Schwarz
http://people.stat.sfu.ca/~cschwarz/CourseNotes/
swirl teaches you R programming
https://www.youtube.com/user/ramstatvid/videos
http://personality-project.org/r/
http://xavier-fim.net/R/eng.html
Rattle Videos
http://rattle.togaware.com/rattle-videos.html
https://www.youtube.com/channel/UCu7MPZwCKjjolSZkxQt6dCQ
R Videos
Roger Peng
https://www.youtube.com/user/rdpeng/videos
R data sets are installed here:
C:\Program Files\R-3.1.1\library\datasets\data
R packages come with R dataset package which is automatically installed containing:
http://stat.ethz.ch/R-manual/R-patched/library/datasets/html/00Index.html
—
https://www.youtube.com/watch?v=Xh6Rex3ARjc
http://www.wekaleamstudios.co.uk/topics/r-environment/base-graphics/
https://www.youtube.com/user/Stuar51XT/videos
https://www.youtube.com/user/Stuar51XT/videos?live_view=500&sort=da&view=0&flow=list
Engineering Data Analysis (with R and ggplot2) https://www.youtube.com/watch?v=TaxJwC_MP9Q&list=PL95AEF8D060866263
https://www.youtube.com/user/marinstatlectures/search?query=commander
http://www.r-statistics.com/2009/10/free-statistics-e-books-for-download/
Book: Discovering Statistics Using R data http://www.sagepub.com/dsur/study/articles.htm
http://www.ats.ucla.edu/stat/r/
“bartlett.test” function to formally test the homogeneity of variances.
https://www.youtube.com/watch?v=CMPn0eJ1zqs
https://www.youtube.com/watch?v=h5EeqsPbL5k
https://www.youtube.com/user/rtechcenter/videos
https://www.youtube.com/watch?v=HVqSUKwMK8Q&list=UU-3UHlLpEa3F-n0WwUU8mAQ&index=14
https://www.youtube.com/user/phrygos/videos
https://www.youtube.com/user/marinstatlectures/videos
R commander rcmdr
http://www.mzandee.nl/statistiek/R/Rmanual_paper.pdf
https://www.youtube.com/user/theoldorganplayer/videos
https://www.youtube.com/results?q=rcmdr+heteroscedasticity
http://pages.wustl.edu/montgomery/teaching/quantitative-political-methods/course-book
Book R commander an Introduction – The Comprehensive R …
prediction interval using “UsingR” package:
https://www.youtube.com/watch?v=xvu7Js35V3M
Book Linear Regression with R and R-commander Linear …
https://www.youtube.com/watch?v=qlLzVTI2lIg
https://www.youtube.com/watch?v=xvu7Js35V3M
https://www.youtube.com/user/theoldorganplayer/videos
==============================================
http://www.statmethods.net/management/subset.html
Sample R code:
https://www.youtube.com/watch?v=Xh6Rex3ARjc
data(airquality)
#list vars
names(airquality)
#showdata
airquality
#plot data
plot(Ozone~Solar.R,data=airquality)
#calculate mean ozone concentration (na´s removed)
mean.Ozone=mean(airquality$Ozone,na.rm=T)
abline(h=mean.Ozone)
#use lm to fit a regression line through these data:
model1=lm(Ozone~Solar.R,data=airquality)
#Weighted to cancel heteroskedasticity
model2=lm(Ozone~Solar.R,data=airquality,weights=(1/airquality$Ozone))
model1
abline(model1,col=”red”)
plot(model1)
termplot(model1)
summary(model1)
model1=lm(Ozone~Solar.R*Wind,data=airquality)
p1=predict(model1,data.frame(Solar.R=100,Wind=1:200))
p1
=============================================
#bring the package PerformanceAnalytics from menu
mycols=read.csv(“C:/Users/…../Desktop/56-2.csv”)
library(PerformanceAnalytics)
chart.Correlation(mycols[c(2,5:6)]) #columns 2 and 5 to 7 are selected
=======================
Vector and list references in R
j=c(5:10)
“[” Index operator is actually a function ‘[‘(j,3)
“[[” Subset operator is actually a function ‘[[‘(j,3)
‘[‘(j,3)
‘[[‘(j,3)
j[3]
j[[3]]
#i is a vector
i <- c(5, 4,3,2,j)
# i is composition of a number of single item vectors this is the first vector in i
i[1]
#Pointing to index one one of the vector
class(i[1][1])
#Pointing to index wants Subset one of the vector
class(i[1][[1]])
#Pointing to index one two Of the vectorWhich doesn’t exist because you have air one dimensional vector
i[1][2] #NA
#Pointing to index one subset to which doesn’t exist in a one dimensional vector
i[1][[2]]
#this is the 6th vector in i And basically the two vectors are catinated
i[6]
s <- c(“s1”, “s2”, “s3”)
l <- c(TRUE, FALSE, TRUE)
#————————————————————-
#A list is a container of other objects.
amirlist <- list(i, s, l, 3,ll=list(i,j)) # x contains copies of n, s, b
##iv is a Subset of the list In index one As a vector identical to numeric vector
iv<-amirlist[[1]]
class(iv)
#iL is a list, This is what is an index one of the list therefore it is list
iL<-amirlist[1]
class(iL)
#what is in the index 5 of the list,Of course it is a list
amirlist[5]
class(amirlist[5])
#The first index of the first index remains a list
b<-amirlist[1][1][1][1][1]
class(b)
#list index [1][2] doesn’t exist because the list is one dimentional
amirlist[1][2]
#list index [5][2] doesn’t exist because the list is one dimentional
amirlist[5][2]
#The first subset of this fifth index of amirlist Is a list of two Victors
amirlist[5][[1]]
#This is identical with the syntax above
amirlist$ll
#The first recursive index of the fifth index remained a list of two vectors
amirlist[5][1][1][1][1]
#The second Subset of what is indexed five doesn’t exist
amirlist[5][[2]]
#To access the value inside the list you have to use substance
#The first subset of the list is a vector and at indexed two has a number
a<-amirlist[[1]][2]
class(a)
#If we get this second subset of the first subset of the list we are getting the number
b<-amirlist[[1]][[2]]
class(b)
#The second Subset of the fifth subset and the second index of the fifth subset is a vector
amirlist[[5]][[2]]
#The The first subset of the fifth subset of the list is another vector
amirlist[[5]][[1]]
#The fifth subset Index to exist and to vector which is identical to the second index of the list in the fifth place
amirlist[[5]][2]
#The second subset of the list the first subset the number 4
amirlist[[1]][[2]]
#2nd Index to second subset of the fifth subset Is a value in the second vector
amirlist[[5]][[2]][2]
#assign 3 to Second subset of the first subset (second vector of first vector)
amirlist[[1]][[2]]=3
Ref:https://cran.r-project.org/doc/manuals/r-release/R-lang.pdf
==========================================================
A good correlation chart but deducer is better
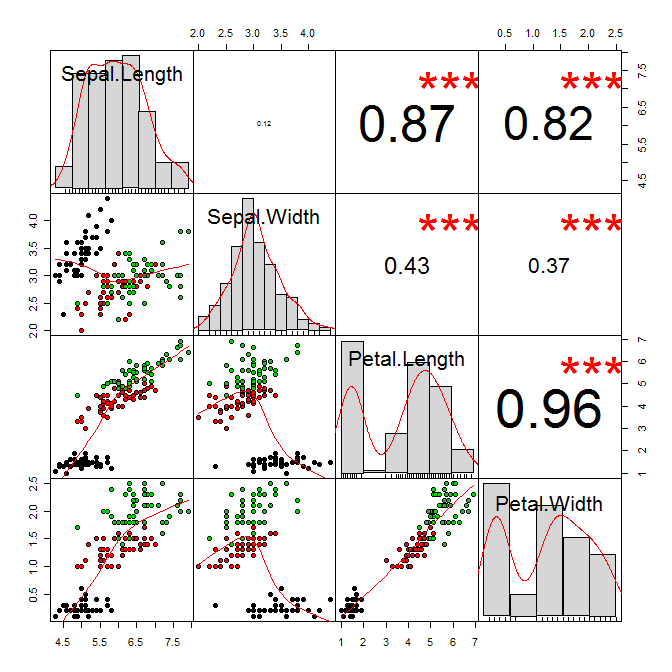
mycols=read.csv(“C:/Users/aghasemi/Desktop/Part1of428questions14Mar2015aft3.csv”)
library(PerformanceAnalytics)
library(corrplot)
length(mycols)
ncol(mycols)
nrow(mycols)
colnames(mycols)
i=1
amirstep=5
j=2
seq(2,262, by=amirstep)
for (j in seq(2,20, by=amirstep))
{
k=j+amirstep
k
corrcheck<-mycols[c(i,j:k)]
M<-cor(corrcheck,use=”complete”)
M
N=M[!is.na(M)]
N
corrcheck
#we can use bg=c(“blue”,”red”,”yellow”) or bg=c(“black”,”blue”,”red”,”green”, “yellow”, “white”), pch=21 ,
# list of pch symbols http://www.endmemo.com/program/R/pchsymbols.php
chart.Correlation(corrcheck, histogram = TRUE, method = “pearson”, col=”black”)
#, lower = “ellipse”, upper = “circle”
}
# the meaning of * double checked with deducer
(0 "***" 0.001 "**" 0.01 "*" 0.05 "." 0.1 1)
#. P ≤ 0.1
#* P ≤ 0.05
#** P ≤ 0.01
#*** P ≤ 0.001
#**** P ≤ 0.0001
============================================
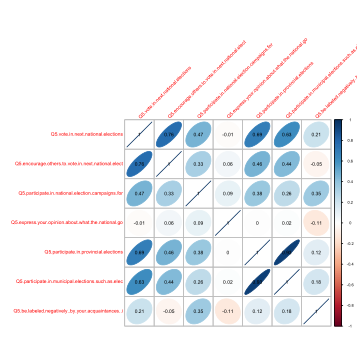
THIS METHOD HAS NO p-vale BUILT IN
http://cran.r-project.org/web/packages/corrplot/vignettes/corrplot-intro.html
mycols=read.csv(“C:/Users/aghasemi/Desktop/Part1of428questions14Mar2015aft3.csv”)
library(PerformanceAnalytics)
library(corrplot)
length(mycols)
ncol(mycols)
nrow(mycols)
colnames(mycols)
i=1
amirstep=5
j=2
seq(2,262, by=amirstep)
k=j+amirstep
k
corrcheck<-mycols[c(i,j:k)]
M<-cor(corrcheck,use=”complete”) # ignore NAs
M
par(cex=0.3) # to control the font size
corrplot.mixed(M,upper=”ellipse”)
#to control the file saved
#png(height=1200, width=1500, pointsize=15, file=”C:/Users/aghasemi/Desktop/overlap.png”)
corrplot(M, method = “color”, addCoef.col=”black”) # a simple nice chart
corrplot(M, method = “ellipse”, addCoef.col=”black”, tl.pos = “s”, tl.srt = 45) # a better chart title at side with angle
============================================
For, While , If, and Print in R
#for (vector counter)
#{
# Statements
#}
#while (constraint condition) // while is a keyword
#//returns bool (true/false) value
#{ //opening curly brackets
# //Statements
#} // closing curly brackets
#definition and initialization of vector
amir = seq(1, 100, by=2)
amir
# vector operation amir^2 is fast
#azi.squared is a vector I created
azi.squared = amir^2
azi.squared
#serial implementation
#Define a dynamic array this empty I created
nilou.squared = NULL
#define a fixed length array for faster operation and initials with NA
nilou.squared = rep(NA, 200)
nilou.squared
summary(nilou.squared)
for (i in 1:50 ) { # or for (i in 1:length(amir)
nilou.squared[i] = amir[i]^2
}
nilou.squared[2]
nilou.squared
if (nilou.squared[2] == 9){
sprintf(“Nice”)
#stop can give Error message
#stop(“hello”)
}else {
sprintf(“oops”)
}
sprintf(“%1.0f”,nilou.squared[3])
print(nilou.squared[3])
print.table(nilou.squared[2:5])
#get rid of excess NAs
#! means not
# FOR EVERY CELL IN nilou.squared put the value in place only if that cell is not NA
nilou.squared = nilou.squared[!is.na(nilou.squared)]
nilou.squared
summary(nilou.squared)
silas.print=NULL
i=1
while(nilou.squared[i]<1000)
{
silas.print[i]= nilou.squared[i]
i=i+1
}
silas.print
the result will be
|
|
dot “.” Now declare Now declare the function Then the dot has special meaning. For all objects with class will actualy call function This is used widely in R, the most appropriate example is function |
Ref: http://stats.stackexchange.com/questions/10712/what-is-the-meaning-of-the-dot-in-r
Cran’s R into: https://cran.r-project.org/doc/manuals/r-release/R-intro.html
===============================================
R (D)COM Server and RExcel
This package contains a DCOM server used to connect a client application (e.g. Microsoft Excel) with R.
R (D)COM Server provides a COM-Interface to R as well as various COM objects and Active X controls for your applications. Additionally, an Add-In for Microsoft Excel is provided to easily use R in Excel and create statistical applications with Excel as the main GUI. The main features of this package are:
-COM server for local and remote use of R
-transfer of data into/from R, including NA, NaN,…
-Active X Controls for text and graphics output
-Installation/Uninstallation
-Repository for R instances for shared and exclusive access
-Many Samples
-Excel Add-In
Is commercial now: http://sunsite.univie.ac.at/rcom.
Author(s)
Thomas Baier and Erich Neuwirth
![]()