
Likelihood is a term to replace the following:
The probability of the current observation(s) if the population constant parameter is Theta.
Likelihood=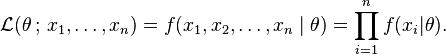
where
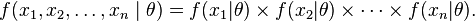
F is the pdf for x given theta
Maximum likelihood estimate for the unknown theta:
The constant theta of the population for which the current observation(s) would be most probable to happen.
we find the best model, among all models with different constant thetas, for which the probability of observations is the most.
We define the maximum, we find for which theta the derivative of Likelihood f(x|theta) is zero.
\frac{\partial f(x|\theta)) }{\partial \theta}=0
Which will give the same result as when we solve

for theta.
========================================
Example:
For the normal distribution 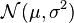 which has probability density function
which has probability density function

the corresponding probability density function for a sample of n independent identically distributed normal random variables (the likelihood) is

or more conveniently:

-
which will be zero when mean of the population is mean of the sample. Therefore the probability of the observed xs is most when mu is xbar.
fortunately Its expectation value is equal to the parameter μ of the given distribution,
![\begin{align}
0 & = \frac{\partial}{\partial \mu} \log \left( \left( \frac{1}{2\pi\sigma^2} \right)^{n/2} \exp\left(-\frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2}\right) \right) \\[6pt]
& = \frac{\partial}{\partial \mu} \left( \log\left( \frac{1}{2\pi\sigma^2} \right)^{n/2} - \frac{ \sum_{i=1}^{n}(x_i-\bar{x})^2+n(\bar{x}-\mu)^2}{2\sigma^2} \right) \\[6pt]
& = 0 - \frac{-2n(\bar{x}-\mu)}{2\sigma^2}
\end{align}](http://upload.wikimedia.org/math/8/9/e/89e3e66bb7b8d209cb953e395faf4ba3.png)
![E \left[ \widehat\mu \right] = \mu, \,](http://upload.wikimedia.org/math/3/3/e/33eb258b6d0c1f03ae61f6fff75e11d6.png)
also
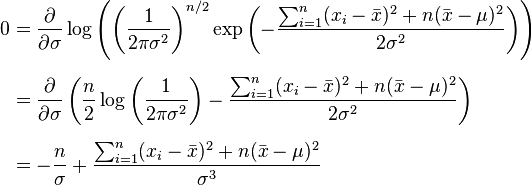
This is zero when

Which means the estimator for variance of population sigma considering our observations is variance of the sample.
However, ![E \left[ \widehat\sigma^2 \right]= \frac{n-1}{n}\sigma^2.](http://upload.wikimedia.org/math/c/e/1/ce1e1bbf24206ceb03470404efbf1303.png)
Which means that variance of the sample is biased a little bit.
http://en.wikipedia.org/wiki/Maximum_likelihood
![]()